스트림의 최종 작업은 무엇입니까?
람다 및 스트림 – 스트림의 정의 및 특성
스트림의 정의와 필요성 요컨대, 컬렉션과 배열을 다루기 쉽게 만듭니다. 기존 컬렉션 프레임워크를 보면 위와 같이 List, Set, Map 인터페이스로 구성되어 있음을 알 수 있다. 더블
sgcomputer.tistory.com
이전 파트에서 배웠듯이 일반 객체와 달리 스트림은 한 번 사용하면 재사용할 수 없다는 것을 배웠습니다.
그 때, 이 사용에 대한 기준은 최종 작업입니다.
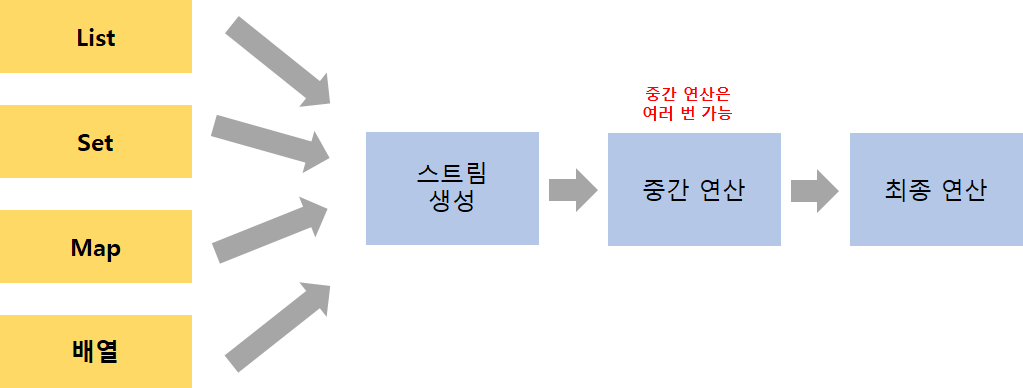
이전에 사용했던 사진을 다시 가져오면 위의 스트림이 위와 같은 과정으로 사용됩니다.
수집 데이터에 대한 스트림 요소를 생성한 후 중간 작업을 통해 데이터를 처리합니다.
이후 최종 연산 과정에서 스트림 요소가 소모되면서 스트림의 사용이 종료된다.
이 부분에서는 스트림의 다양한 최종 동작 방법에 대해 공부할 것입니다.
최종 연산 – forEach() : 출력 결과
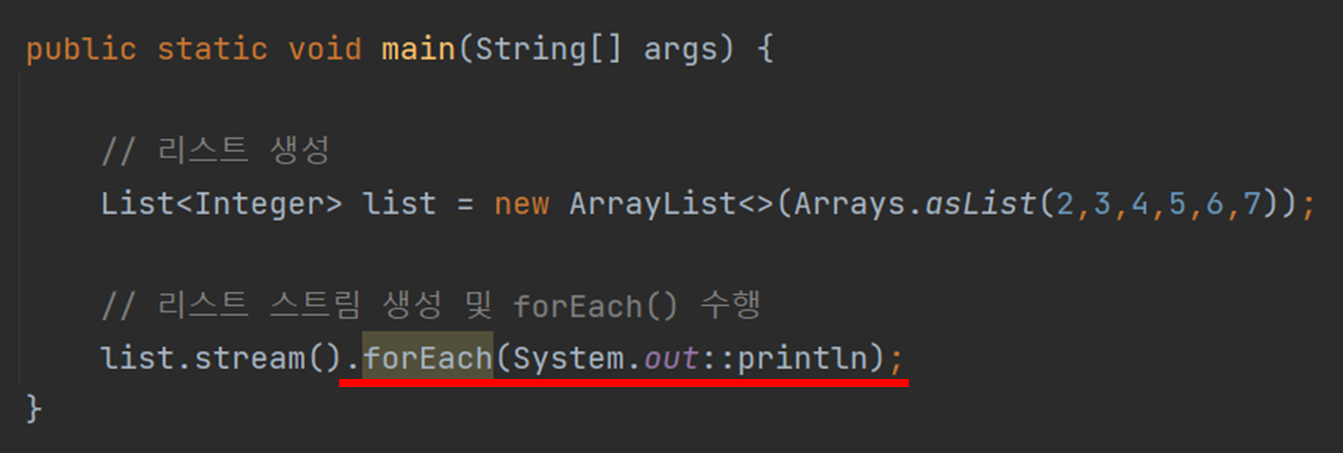
이미 많은 예제에서 사용된 forEach()는 스트림에서 데이터를 출력하는 함수입니다.
forEach() 메서드는 반환 유형이 무효이므로 아무 것도 반환하지 않습니다.
그리고 인수로는 Consumer 인터페이스 형태의 람다식만 전달된다.
최종 작업 – allMatch(), anyMatch(), noneMatch: 일치 조건
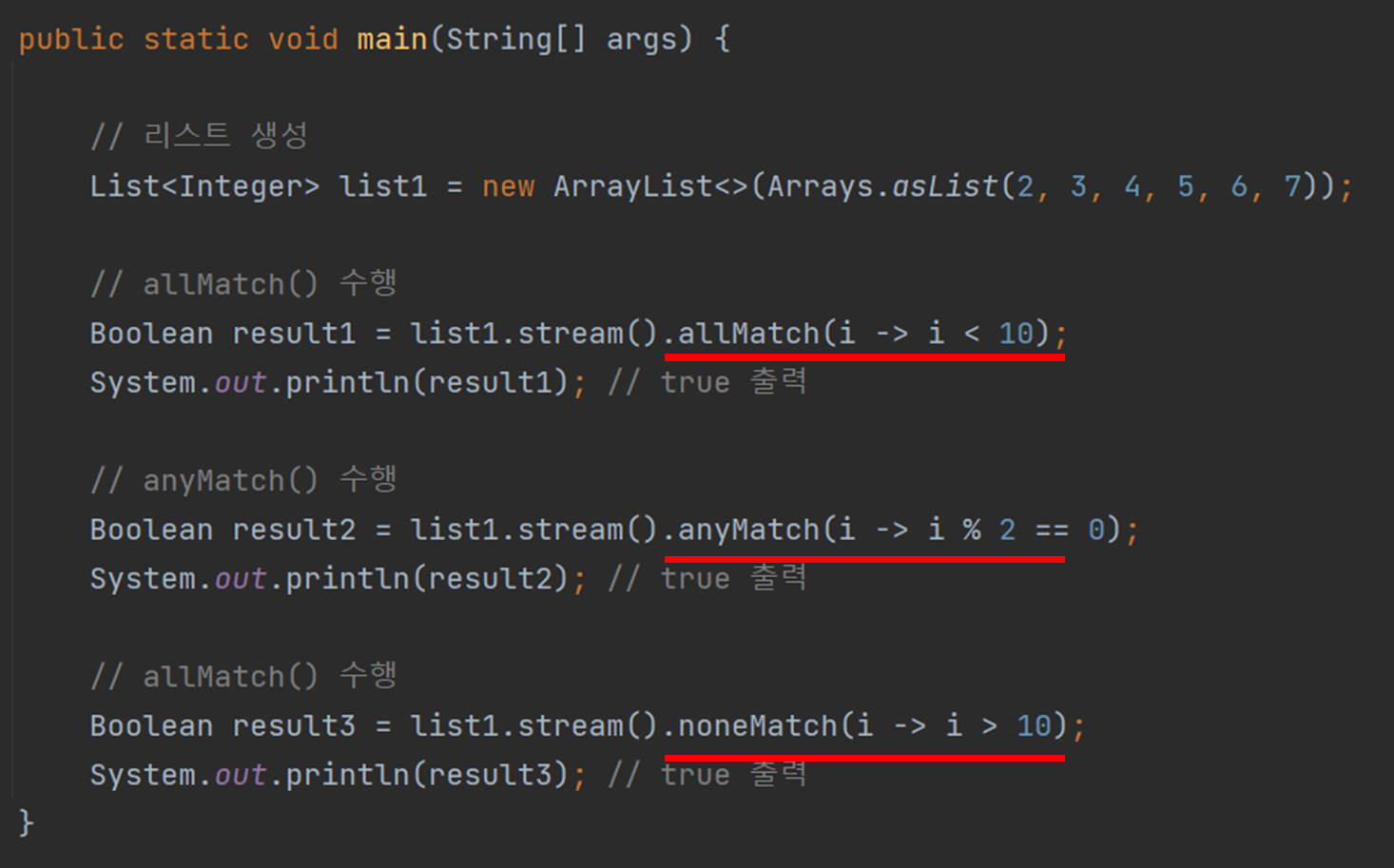
이 단락에서 소개할 메서드는 조건의 결과가 일치하는지 확인하는 기능입니다.
– 올매치() : 전달된 모든 인수가 조건을 충족하면 true를 반환합니다.
– 애니매치() : 전달된 인수 중 하나라도 조건을 충족하면 true를 반환합니다.
– nonMatch() : 전달된 모든 인수가 조건을 충족하지 않으면 true를 반환합니다.
위의 그림과 방법 설명만 봐도 사용 방법이 어렵지 않다는 것을 알 수 있습니다.
세 메서드 모두 반환 유형으로 boolean을 가지며 Predicate 인터페이스의 람다 식을 인수로 받습니다.
최종 작업 – findFirst(), findAny(): 일치 조건
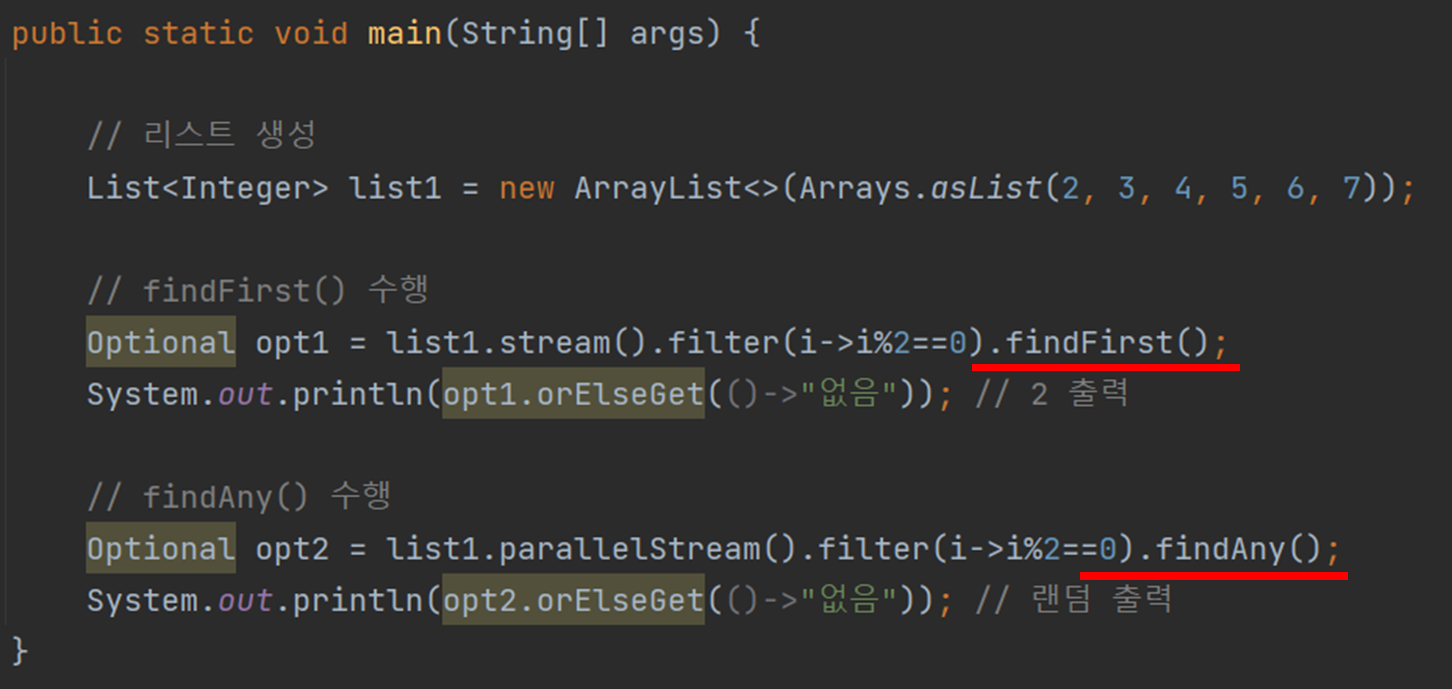
– 먼저 찾기() : 조건식과 일치하는 요소 중 첫 번째 요소를 반환
– 찾기() : 조건식과 일치하는 요소 중 임의의 요소를 반환
filter()와 함께 findFirst()와 findAny()를 함께 사용하는 것을 보면 편리하다.
filter()를 통해 필터링된 요소 중 findFirst()는 첫 번째 요소를 반환하고 findAny()는 임의의 요소를 반환합니다.
findAny()는 parallelStream()이 병렬 스트림인 경우에만 제대로 작동합니다.
일반 직렬 스트림이면 findFirst()와 같이 조건을 만족하는 요소 중 첫 번째 요소를 반환합니다.
그리고 한 가지 더 중요한 점은 findFirst()와 findAny() 모두의 반환 유형이 선택 사항이라는 것입니다.
조건을 만족하는 표현식이 없을 때 NullPointException을 방지하기 위함입니다.
최종 작업 – reduce(): 스트림에 누적 작업을 수행합니다.
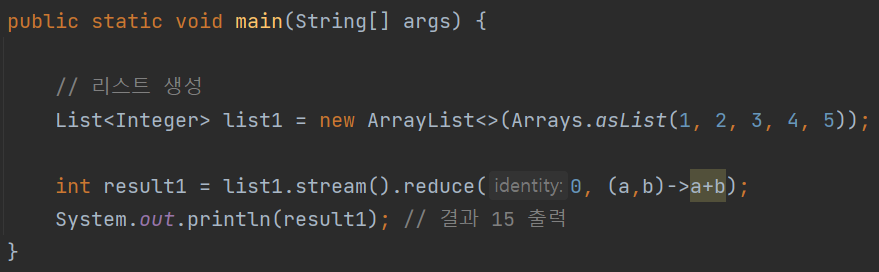
축소는 표면적으로는 복잡해 보이지만 실제로는 그리 어렵지 않습니다.
reduce 인자로 제공되는 숫자는 초기값, 스트림 요소의 연산 결과, 스트림 요소 총 3개이다.
계산 과정은 다음과 같이 설명됩니다.
– a의 초기값은 지정된 숫자 0에서 시작합니다. 작업이 진행되면 a는 a+b의 값을 갖습니다.
– b는 연산이 진행됨에 따라 리스트의 요소를 순차적으로 갖는다.
– 즉, 계산 과정에 따른 값의 변화는 다음과 같습니다.
– 0+1 = 1
– 1+2 = 3
– 3+3 = 6
– 6+4 = 10
– 10+5 = 15
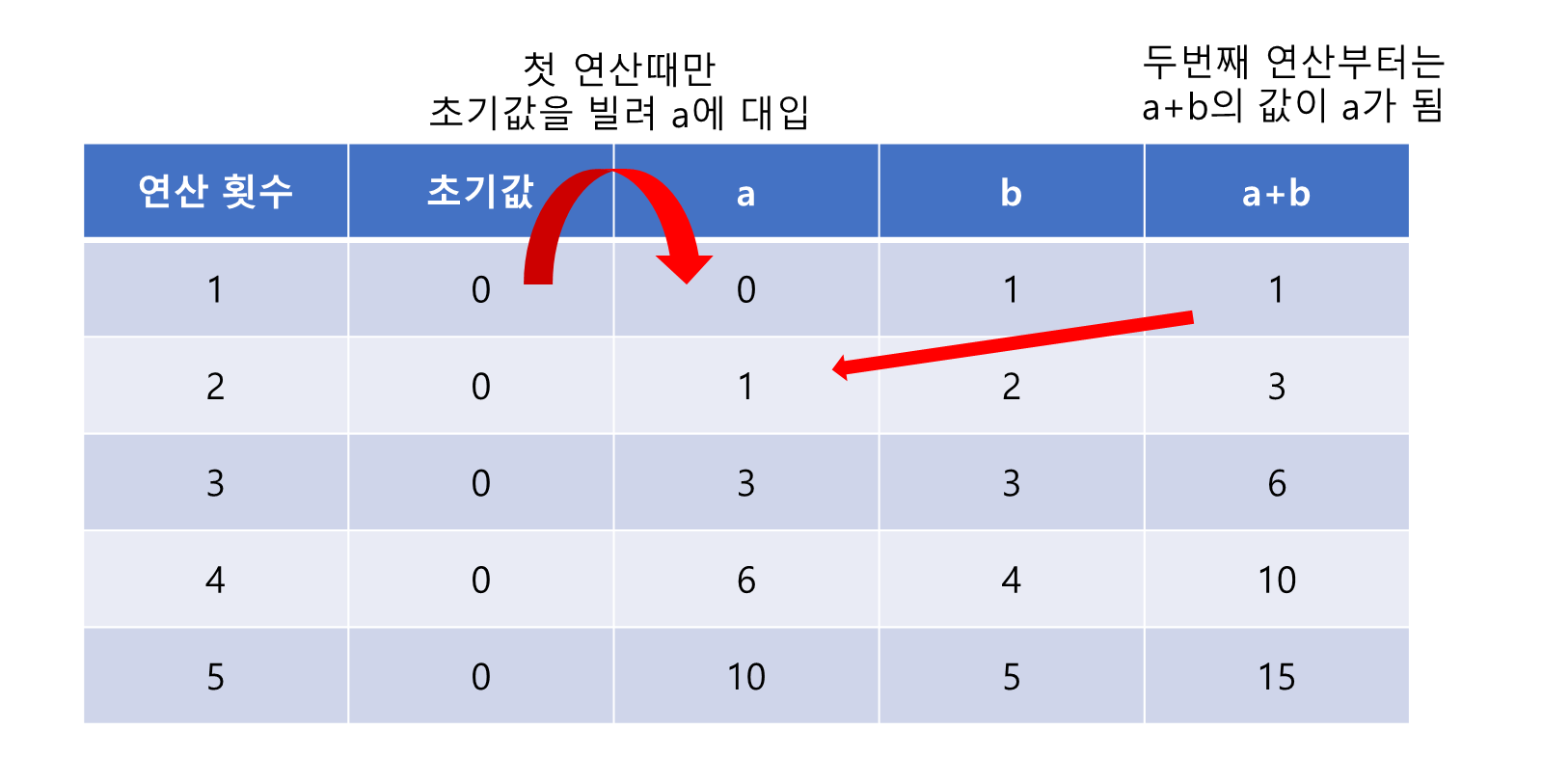
표로 제시하면 위와 같다고 볼 수 있다.
a는 첫 번째 연산에만 초기값을 빌려오고, 다음 연산에서는 연산 결과인 a+b 값을 사용한다.
이와 같이 reduce는 모든 요소에 대해 누적 연산을 수행할 수 있으며, 이를 이용하여 다양한 연산을 수행할 수 있습니다.
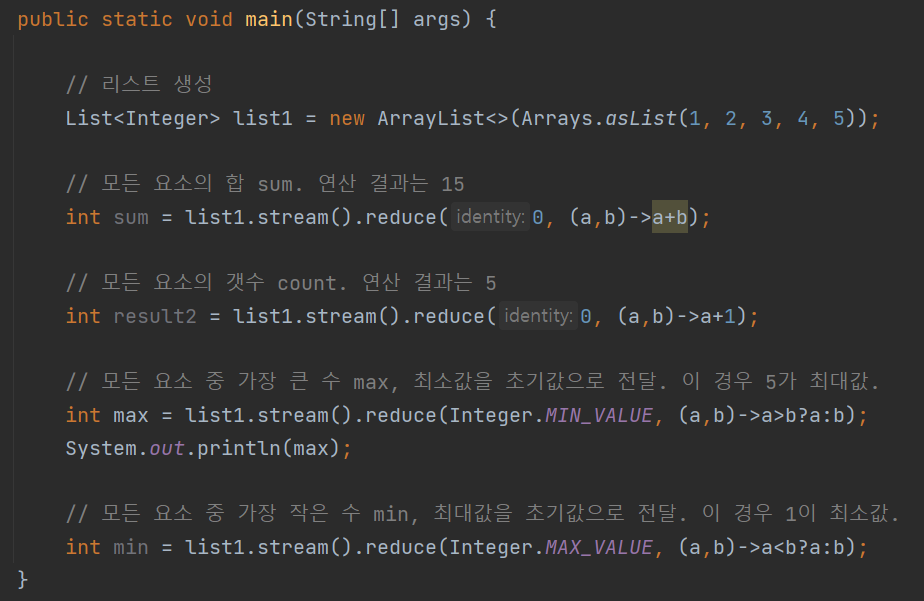
위의 그림을 통해 reduce()의 인자로 어떤 초기값과 표현식을 주느냐에 따라 결과가 달라지는 것을 알 수 있다.